Self-driving is full of technical challenges, and as a company focused on delivering the benefits of self-driving technology safely, quickly, and broadly, Aurora is solving these challenges using a variety of disciplines such as machine learning, computer vision, simulation, and vehicle log ingestion. Much of the work we do is extremely resource-intensive in terms of computing power. On any given day, we process 5-12 million tasks through our computing infrastructure, ranging from simulations, vehicle log processing, high-resolution map building, perception inference, calibrations, and more.
Our engineers, scientists, and developers are based across the United States and work different hours, in different time zones, with wildly variable resource demands. This means our systems must be able to run in a highly automated fashion and scale seamlessly with whatever our teams throw at them. We have to design and build tools for a broad range of use cases, ensure that we keep ahead of the curve as our demands for large-scale computing continue to increase, and maintain the highest levels of stability and reliability in our production systems.
Let’s take simulation as an example of a discipline with tons of supercomputing applications. Simulation is a huge focus for Aurora as it allows us to experiment and validate the Aurora Driver software in a “virtual world” that is not limited by the number of vehicles we have on the road, or the number of hours in a day. Simulations are also critical gating tests for changes to the Aurora Driver software to ensure the system behaves as expected before it is loaded onto vehicles for use in the real world. As one might expect, running simulations equivalent to driving 50,000 trucks simultaneously and continuously requires a huge amount of computing power.
The Simulation team is just one of many teams that needs quick and easy access to a system that is efficient, robust, and highly scalable in order to monitor workloads, find and debug issues, and iterate on designs. If every team had to create and manage their own computing platform, it would add additional overhead and cost and likely result in a lot of duplication of effort.
To further illustrate this point, take a look at the following graph of computing tasks completed successfully in the weeks leading up to our Aurora Illuminated event, where we showed off the Aurora Driver to our investors and the world:
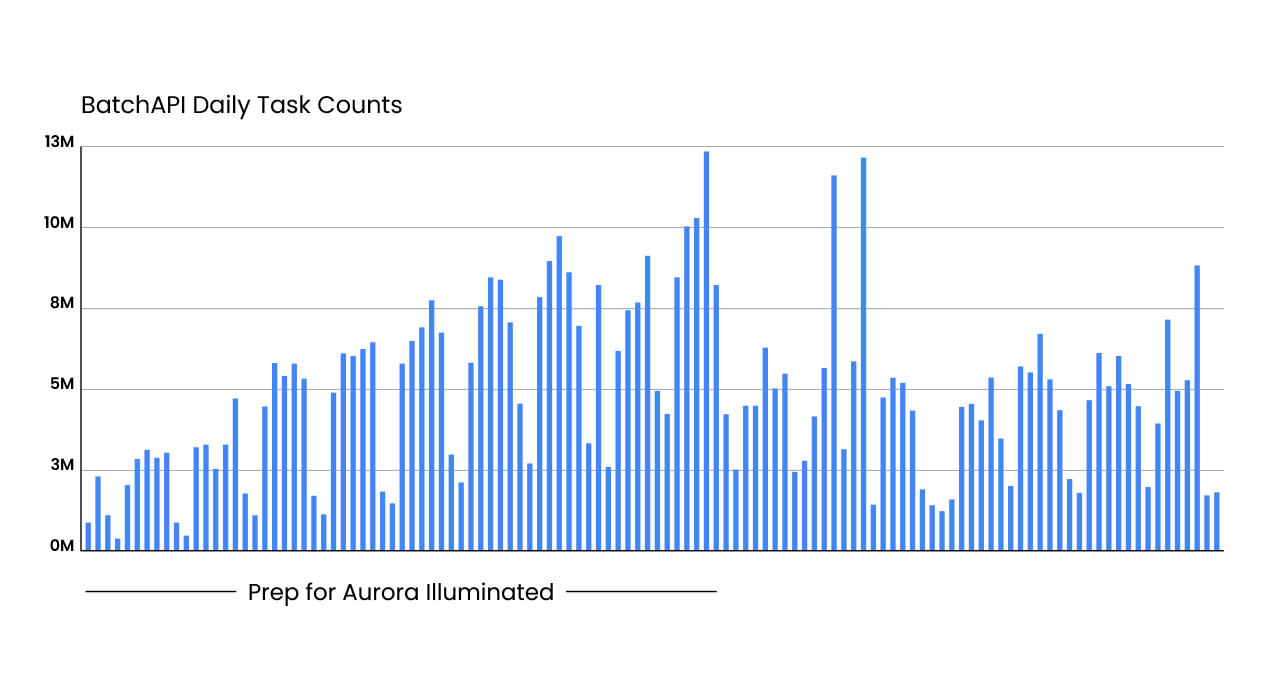
Figure 1.
As you can see in the time before the event, we saw a 3x increase in demand for our computing platform as teams across the company worked hard to make sure everything was ready to go. Our systems were able to automatically scale to meet this demand, all while maintaining 100% reliability and zero outages of any mission-critical systems. None of that would have been possible without a robust, flexible, and highly-scalable system that all teams can leverage.
So how does Aurora’s Compute Infrastructure team do all this and create and manage backend systems that enable our engineers, data scientists, and researchers to continue advancing self-driving technology?
Batch API
At the heart of the Compute team’s platform is a batch-processing system that we developed in-house known as Batch API. Its primary design philosophy, like any batch-processing system, is “throughput over latency.” However, Batch API has some unique features that allow us to flip that concept and provide “latency over throughput” for teams who have more strict requirements around timeliness. It also has a strong focus on efficiency and cost-effectiveness as it is designed to operate in both on-premises data centers and cloud environments.
Batch API is a collection of services and components (almost exclusively written in Go) that runs workloads (or “jobs”) on an elastic pool of Kubernetes pods (or “workers”). Aurora engineers, scientists, and developers (who we refer to as “users”) create jobs that consist of a collection of processes to run, called “tasks,” which are then executed by the workers according to how the user has defined the task ordering, represented by a directed acyclic graph (DAG) of inter-task dependencies. Batch API creates and manages workers for each job and coordinates task execution based on a job’s DAG. Jobs can run in multiple computing clusters of computing systems, or even multiple regions, completely transparently to the user who created them.
This level of automation is tricky at best, but compounded even further by the additional complication of managing the actual computing resources that Batch API uses to run its workers and execute its tasks. We leverage the power of Kubernetes and Amazon’s Elastic Kubernetes Service (EKS) to manage the raw computing resources and, as we’ll discuss, the Compute team has come up with clever ways to use these products to keep ahead of our teams’ demands.
Disclosure: Amazon has invested in Aurora.
Why build our own system?
The answer is simple; no existing technology could address all of our needs:
-
Understandable tasks - Whenever you venture out into the world of highly-parallel computing, you inevitably find yourself trying to debug a failure in one small piece of a much larger computing job. As these jobs get more complex, the ability to understand the individual bits can get harder and more abstract. Even for a job with a million tiny bits, users should be able to find one task and understand it.
-
Heterogeneous workloads - Our teams run a variety of workloads, many of which they haven’t even developed yet. If our system is unable to manage different kinds of jobs and tasks smoothly, we either force users to limit the kinds of workloads they run, or we end up creating hacks or bespoke solutions that incur tech debt.
-
Fault tolerance - Our systems and our team’s workloads must be resilient. A system that doesn’t break and shut down completely each time a fault occurs will save us valuable time and ensure that our teams are not constantly disrupted.
-
Resource efficiency - Our systems must scale to meet our users’ demands, and we want to be able to make smart decisions on their behalf. Computing resources (and our colleagues’ time) are not infinite so we need a system that can provide exactly the resources needed, at exactly the right time, and have the tools to tell Aurora’s Compute Infrastructure team when this is not happening so that we can improve the system.
-
Single entrypoint - Our teams shouldn’t have to learn and maintain many different systems. Rather, they should only need a single set of APIs and a common framework that they can leverage with confidence.
Understandable tasks
Our team has had extensive experience with some of the most popular open source batch systems over the years. Such systems have compelling feature sets and work well for certain use cases (such as running SQL queries over massive data sets). However, one of the great challenges with using many of these systems to run highly-parallel computation is determining exactly where a failure has occurred.
For example, the common map operation (part of the ubiquitous MapReduce pattern), which runs a user-defined function on each element of a dataframe lasting several minutes or even hours, can fail in an unexpected way on a particular element.
Many open source batch systems do not provide workload-agnostic means of determining the precise element (or set of elements) upon which the function failed. The process of debugging the function on the input that causes it to fail is thus tedious and brittle.
The reason for this is that “task inputs” are often represented as collections of records rather than individual records. The high cardinality of records in the input of a typical job means that storing per-record debug information is impractical and slow. This speaks to the fact that many batch systems were designed to execute a small number of well-understood and well-behaved functions (such as those in the SQL standard) on trillions of small records (like click events).
For our purposes at Aurora, the batch system we use must instead execute novel algorithms on millions of large chunks of data (such as snippets of robotic sensor data), so it makes much more sense to structure the problem as “one function performed on one element equals one task.” The “function” in this case is typically a unix process definition with parameters specified as unix process arguments. In this way, when one task among thousands fails on some input data, the user can quickly run the process locally in the debugger on the exact set element that produced the unexpected behavior.
Massive DAGs
A challenge with scaling many existing workflow systems beyond fairly simple, static DAGs, is the granularity of dependencies. There are many cases where the parallelism needed for a given step is not known ahead of time, or is higher than what many systems can generally handle. This leads to situations where one system is used to define a relatively static DAG (the workflow component), and steps in this DAG negotiate with other large-scale batch systems to perform highly parallelized computation (the embarrassingly parallel component). This pattern, which we call coarse-grained dependency management, results in increased whole-DAG runtime (and thus the runtime of users’ code) in two ways.
First, the critical path becomes the sum of the longest-running task in each step, as illustrated below:
Figure 2.
Second, coarse-grained dependency management creates large spikes in resource requirements for the cluster. At the beginning of each coarse step, the scheduler ramps up parallelism rapidly and then tasks begin to schedule and complete. Cluster resource demand spikes up immediately. At the end of the step, a handful of long-tail tasks might still be running and must be completed before the next wave of tasks is unblocked. When the final task in a step completes, the next step creates a new spike in the same fashion.
This process is inefficient and spikes in resource demands cause an increase in overhead. It takes time to scale the necessary resources up (or down) in a cluster. During that time we are either forced to queue work or pay for excess capacity. We needed a workflow system that is able to handle dependency management within each DAG dynamically.
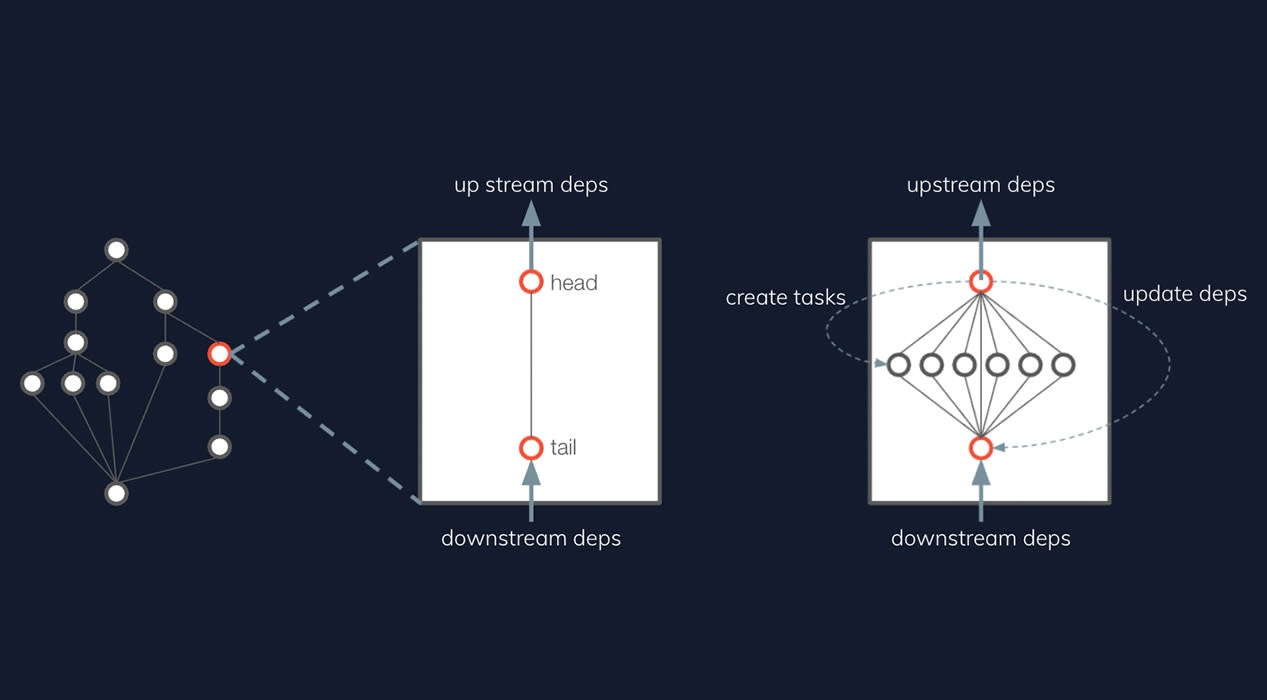
Figure 3. An example of a dynamic DAG.
Batch API solves these problems by implementing what we call “fine-grained dependency management.” As soon as a task completes, its dependent tasks are queued immediately. This “eager execution” of tasks creates a more uniform demand profile throughout the lifetime of the job represented by the DAG, which helps alleviate cluster strain and enables Batch API to handle massive jobs of up to 1 million tasks.
By allowing massive (1M+ nodes and edges) dynamic DAGs, a natural (and much shorter) critical path can emerge, resulting in faster run times and more efficient workloads.
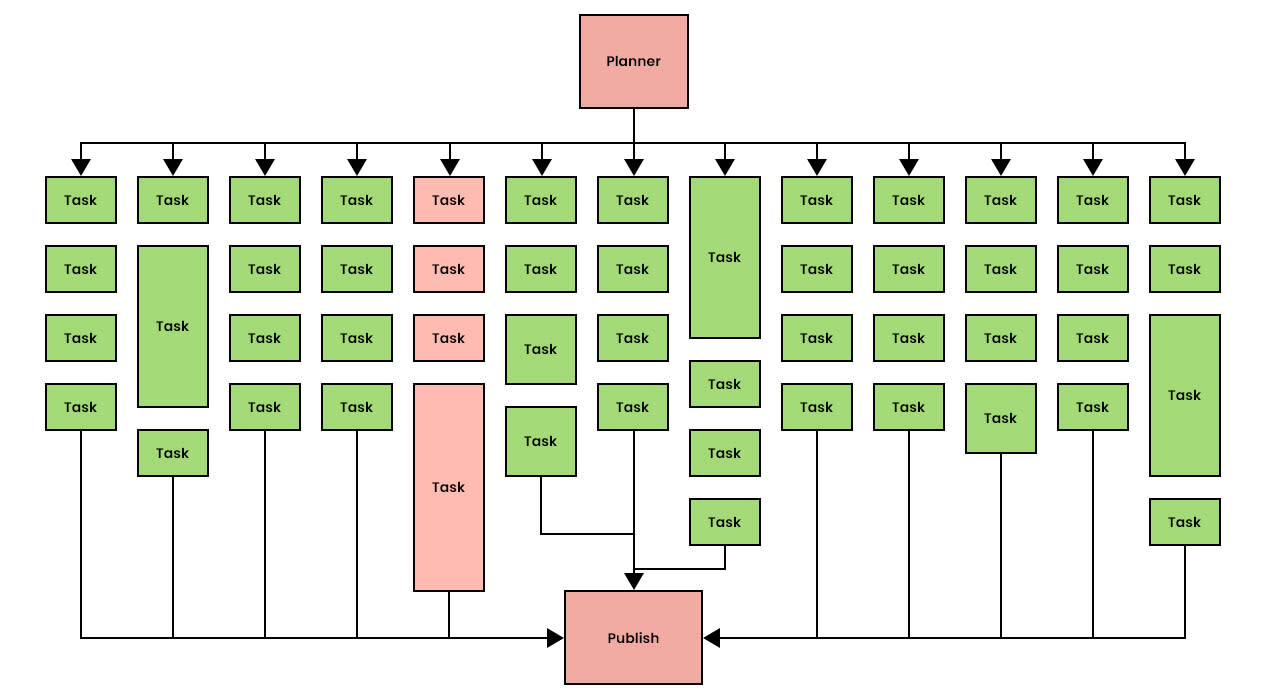
Figure 4.
Worker reuse
To run in cloud environments, the batch system we use needs to make good decisions about what resources are necessary and how to apply them to users’ workloads. There are two basic scheduler models to choose from:
-
One task equals one worker - Every task or step in a DAG requires its own worker. The main drawback with this approach is the overhead incurred due to pod startup being duplicated for every single unit of parallelism (step) in a DAG. Every time we need to run a task, we have to create a new pod and incur all that startup latency again.
-
One worker runs many tasks - A worker can run many steps or tasks in a DAG. Workers are decoupled from tasks and worker pods are provisioned to tasks from a centralized queue until the queue is drained. With this approach, pod startup cost is incurred only when new workers are needed, which can either be done as a fixed pool or dynamically based on the current backlog of tasks.
Batch API uses the “one worker runs many tasks” model, with an optimization. Rather than provision a worker pool of fixed size (which can be potentially wasteful), Batch API will create workers as needed based on the current queue of tasks. This is similar to Apache Spark’s dynamic allocation, but whereas Spark attempts to create workers such that all queued tasks can run concurrently (or hit some upper bound), Batch API uses an algorithm called “worker reuse-targeting.”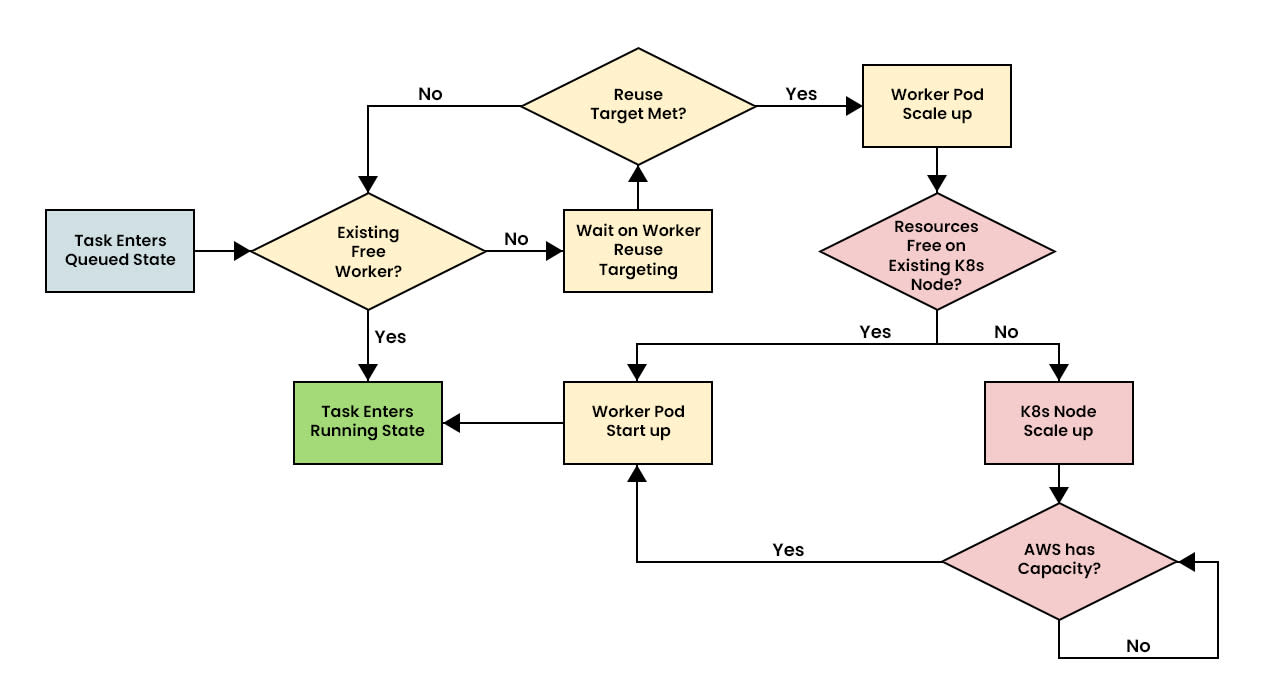
Figure 5. The lifecycle of a task, from Queued to Running.
Worker reuse targeting is an exponential decay function, with a tunable half-life, applied on a per Kubernetes namespace basis. Its purpose is to determine when to wait for existing workers to become available and when to provision new workers.
Each time a new worker is created, there is an inherent overhead runtime penalty incurred while waiting for the worker to start up and get to a ready state to run tasks. If a job’s tasks are extremely short lived, it’s likely more efficient to continue using the workers that have already been provisioned rather than create new ones. Worker reuse targeting attempts to make this calculation and determine if more workers would result in an overall more efficient runtime, or if it is better to stick with the existing workers. By applying this kind of cost/benefit analysis for all jobs, Batch API can maximize the efficiency of the entire system.
Automated resource tiers
With nearly every batch scheduler we’ve used over the years, memory management is a critical problem. Most parallel workloads use a highly variable amount of memory across tasks, particularly when task inputs are geospatially divided. In our experience, the vast majority of tasks use less than a gigabyte of RAM, with a small but unpredictable set of tasks using upwards of 30 GB.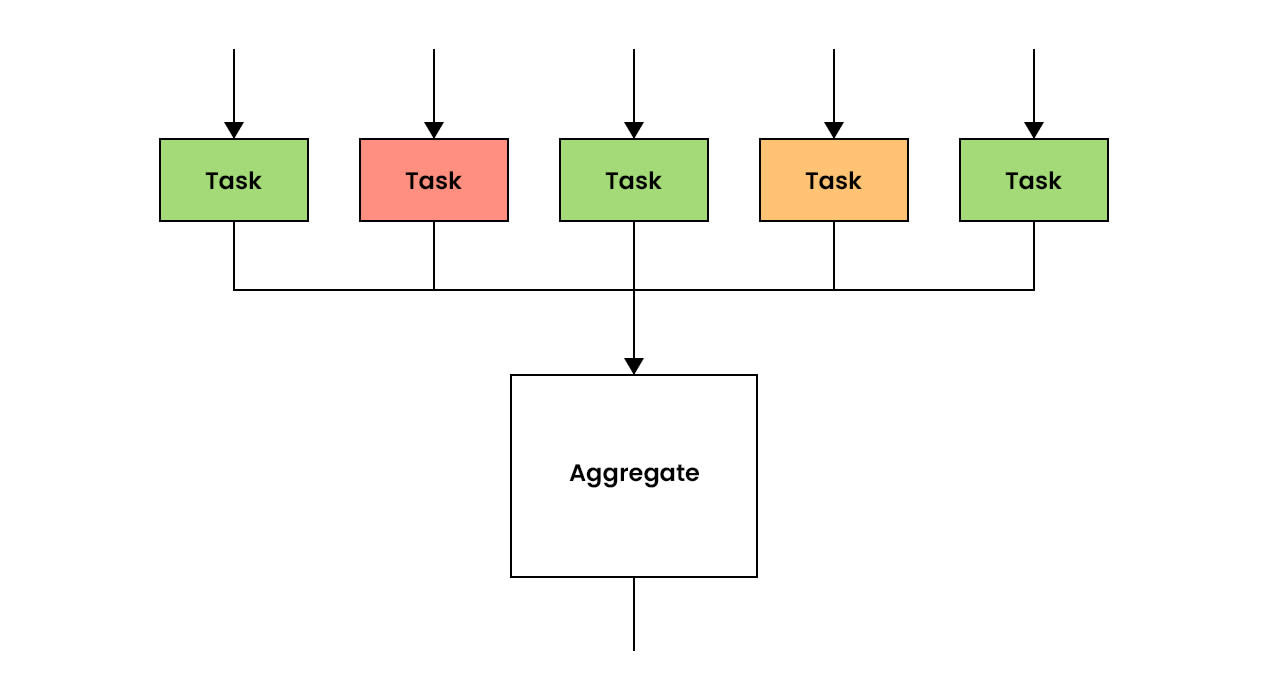
Figure 6. A job with three completed tasks (green) and two running (red/yellow), where red indicates a task has reached its memory limit.
When this situation inevitably arises, users are forced to allocate to every task in the job a resource profile that accommodates the largest task. In a job running 1000 concurrent workers, this means the RAM allocation footprint of the job is over 30 TB, while the RAM utilization footprint is closer to 2 TB.
This is inefficient. There would be much less of a disparity if users could specify resource tiers instead. Essentially, a user could give a task multiple worker configs. If the task fails on the first worker config due to resource exhaustion, subsequent worker configs could take over. Rather than giving a task the maximum amount of memory, users could instead specify a P95 (or thereabout), reserving the larger memory footprint for the very small number of tasks that need it.

Figure 7. Both tasks have failed, the left one due to out-of-memory, the right due to some other error.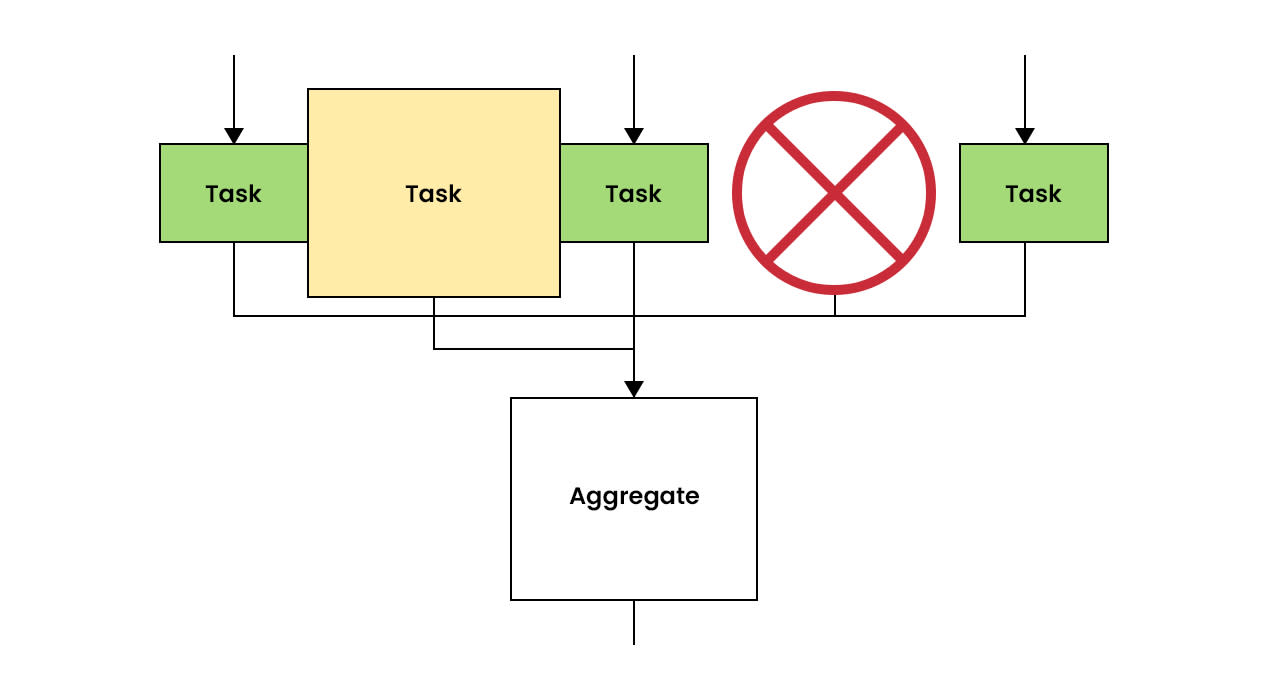
Figure 8. Because the task on the left failed with an out-of-memory error, it is retried with a larger worker.
Let us consider Spark as an example—historical data on Spark memory consumption is difficult to collect, but the following table was taken from the metrics collected on one of our clusters, broken out by Kubernetes namespace. These numbers are fairly typical of the cluster when under moderate load.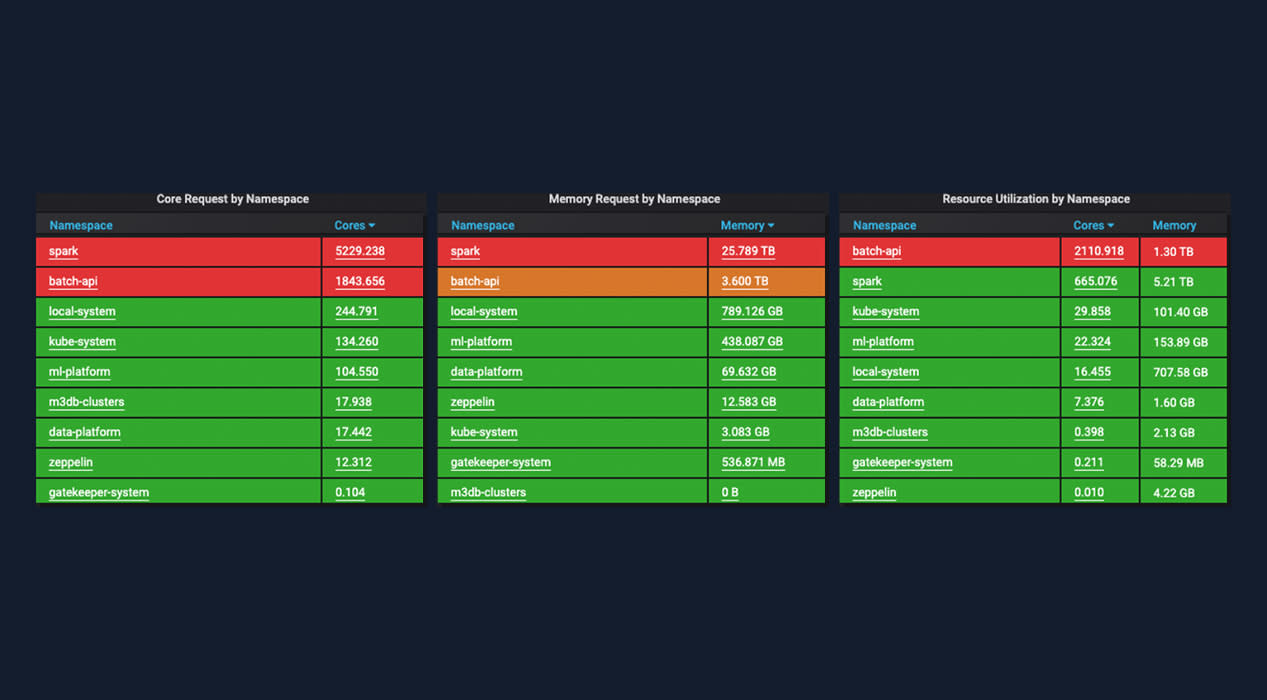
Figure 9. CPU and RAM Requested vs. Used for various Kubernetes namespaces.
In the center column of the above table, Spark is requiring 25.8 TB to Batch API’s 3.6 TB. To get a more complete picture, we can look at the cores each framework is actually using as a proxy for “computation being accomplished.” Batch API tasks are using a bit more than three times the number of cores, so in this particular instance, Batch API tasks are accomplishing three times the amount of work with roughly a seventh of the memory footprint when compared to Spark, for a combined price multiplier of 21.
The exact numbers fluctuate, but we estimate that Batch API is approximately eight times cheaper per unit of computation compared to Spark. The disparity between the memory multiplier (21) and the cost multiplier (8) is due to the fact that once Batch API users have made use of the resource tiers feature to optimize memory, their workloads tend to become CPU-bound.
Architecture
Given these critical needs and the limitations of existing batch-processing technologies, Aurora’s Compute Infrastructure team designed Batch API with three core services:
Gateway API - This is a highly-available stateless service written in Go, using Protobuf for API definitions. The Gateway API is responsible for all user-level interactions and writes directly to the backend database. This allows us to maintain a good user experience while performing maintenance on the rest of the system, and prevents issues in other parts of the system from impacting our users’ ability to submit new work or query for status.
Runner - The Runner, a sharded stateful service written in Go, is responsible for executing and managing all user jobs and tasks across all clusters. Isolating the scheduling and execution functions of the system into the Runner and away from the user-facing interfaces in the API gives us a lot of flexibility in how we make updates or troubleshoot problems. For example, if a single job is creating too many tasks such that the Runner shard is unable to keep up, this will result in a disruption to other jobs. If we had only a single shard, this issue would affect all jobs and could even break the system, but since we have multiple shards, the disruption is limited to only the jobs within that problematic shard.
TaskHost - The TaskHost is responsible for launching user tasks and reporting their results to the Runner. It’s a lightweight binary, written in Go, that is deployed to all Batch workers at runtime and interacts with the Runner via Protobuf APIs. Using a runtime installation of the binary means that it can be upgraded by a central team without needing to coordinate with customers. It also allows a wider range of base images, such as distroless, where support for traditional package management is limited. We recently leveraged this capability when we deployed a new job statistics collection feature to Batch API. Each TaskHost now tracks CPU, memory, and GPU usage for all processes launched by each task and reports this data back to the Runner to be saved to the database and exposed to users via the API. Because the TaskHost is deployed at runtime, we were able to enable this feature for all users with zero downtime, and no coordination needed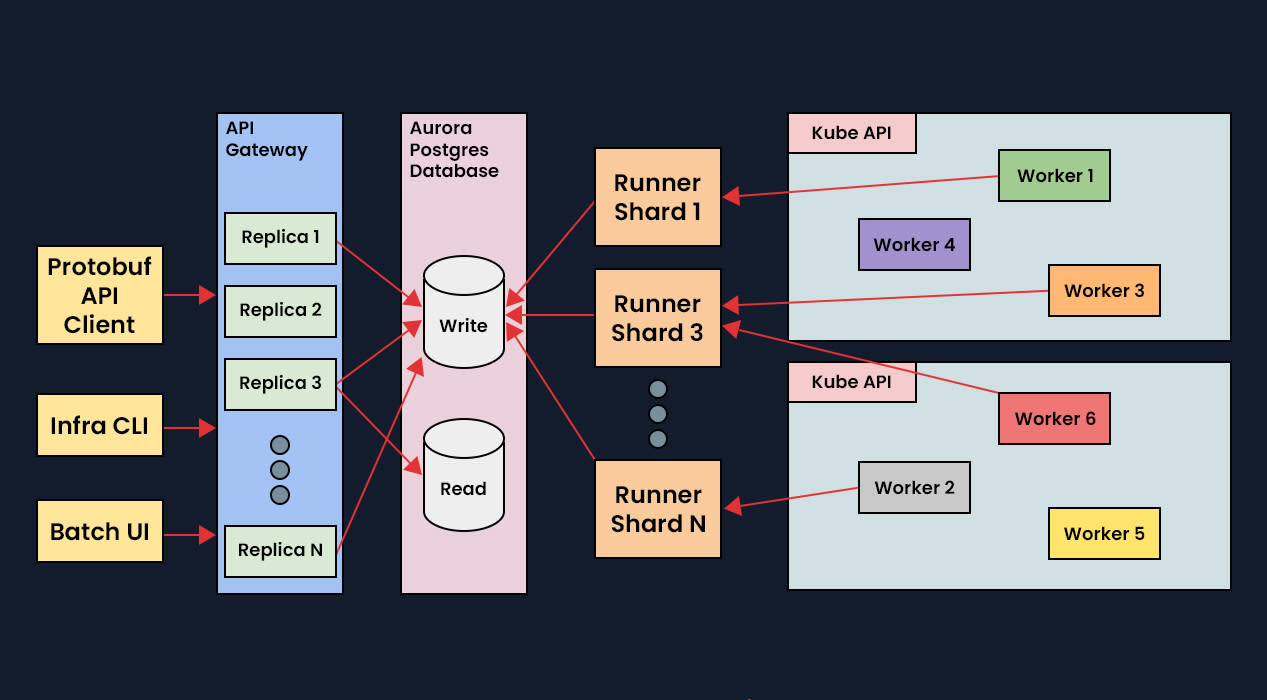
Figure 10.
Now that we’ve defined our computing needs and the kinds of features we’ve developed to meet them, we’ll explore how we deploy and manage the raw computing power necessary to meet our goals. In our next post, we’ll dive into the Kubernetes ecosystem and discuss how it helps us scale our system to meet our teams’ ever-growing demands for large-scale computing.
{kind=link}