The Atlas: Our HD Mapping System

How we design the lightweight, scalable maps that serve as a foundation for the Aurora Driver.
Most of us are better drivers in places we’ve driven before. We know we should drive cautiously in areas where there might be cyclists, we learn when to yield in complex intersections, and we avoid stress (and honking) by changing lanes early out of an exit ramp we know is coming up. Self-driving vehicles also benefit from foreknowledge about their route, which they get from specially designed high definition (HD) maps. These maps are extremely detailed and contain far more information than those used in typical in-car navigation systems.
We’ve been developing our own HD map for the Aurora Driver called the Atlas. The Atlas contains information about static scenery and road infrastructure, making our Driver more efficient by reducing the amount of data it has to process in real time. For example, we build stop signs into the Atlas so our Driver always knows they’re coming, even when they’re faded or hidden behind a parked car.
Without thoughtful design, HD maps can become a morass of dense, heavyweight data that requires significant time and resources to maintain. At Aurora, we view three pieces as critical for maps that enable the Aurora Driver to be deployed safely, quickly, and broadly: (1) the right content, at (2) the required accuracy, and (3) the design, data, processes, and tools that enable rapid updates at scale. We’ve optimized every part of the Atlas’ design with these goals in mind.
Read on to learn more about our approach to developing this foundational piece of the Aurora Driver.
Atlas Content
We build all of our Atlas content entirely in-house to ensure we have the quality of data we need exactly when we need it. This also allows us to more rapidly iterate on the Atlas to improve the Aurora Driver.
Our engineering and map operations teams generate two primary types of Atlas content: world geometry and semantic annotations.
World geometry: We combine sensor data collected from our self-driving vehicles to automatically generate 3D models of buildings, vegetation, and other static objects in the world. We’ve developed a sparse representation of this world geometry that is lightweight enough to support over-the-air updates while still allowing the Aurora Driver to determine its location within the Atlas quickly and accurately.

Semantic annotations: Our map operations team draws important road elements such as lanes, stop signs, and traffic lights on top of the world geometry. To keep the Atlas as small and efficient as possible, we create only those annotations that have a clear benefit to self-driving operation and then thoroughly test them before we mass produce.

Together, these data layers support almost every part of the Aurora Driver’s software system. Localization determines the vehicle’s position in all 6 degrees of freedom relative to the Atlas by matching up stored geometry data with what our sensors are “seeing” in real time. Perception uses both the geometry and the annotations to better classify and track objects, and Motion Planning uses the annotations to prepare for maneuvers like turns and stops.
The Required Accuracy
There’s no point in having the right content if you can’t place that content accurately. Our Atlas design maximizes our ability to place content very accurately relative to the self-driving vehicle while still enabling fast and efficient updates. A key element of our strategy is keeping the Atlas locally, rather than globally, consistent.
What is local consistency?
Map content is described by its relationship to some 3D coordinate frame, which we call an anchor point. In globally consistent maps, like the ones typically used for navigation on mobile phone apps, all data is laid out in relation to a single frame. For example, the maps in some GPS applications use the Earth Centered, Earth Fixed (ECEF) frame, whose anchor point sits in the center of the Earth.
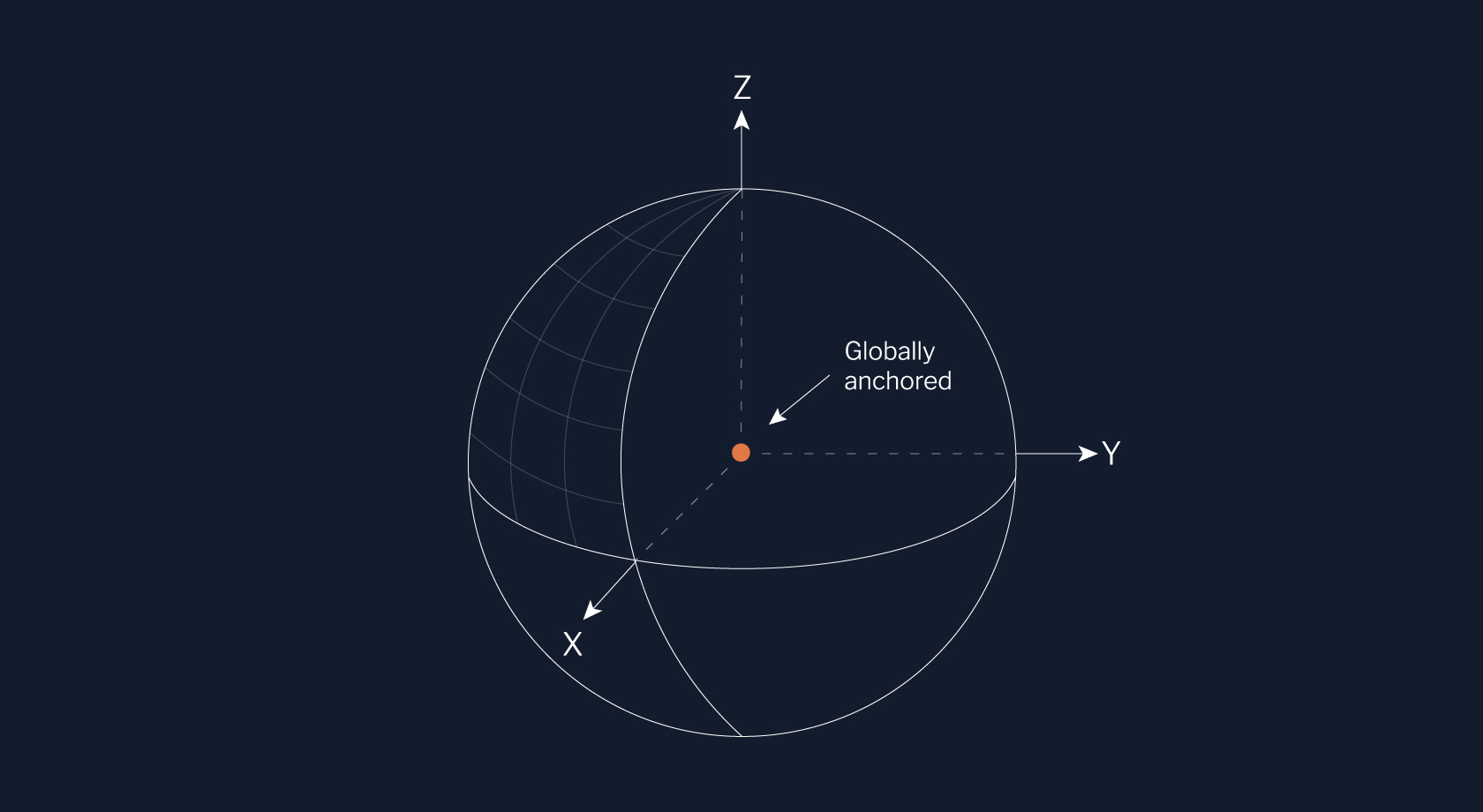
In contrast, the Atlas is laid out in relation to multiple frames. The data inside certain pieces might use the same frame (locally consistent), but the data between those pieces doesn’t (not globally consistent). This means that we describe all of our map content in relative terms. For example, each segment of a lane is described by where it is in relation to its predecessor and successor segments.
If you’re used to thinking about the world as one big map, forgoing global consistency might seem counterintuitive. However, our team has found that our relative map representation allows us to build high-quality maps quickly while preserving accuracy where it matters most for self-driving.
Why we build a relative Atlas
Trying to achieve global consistency comes with a price.
First, the processes used to make maps globally consistent must “warp” data. It’s a bit like trying to solve a jigsaw puzzle with a set of slightly imperfect puzzle pieces. If you want to solve the whole puzzle, you might need to bend, squish, or otherwise alter the individual pieces to make them fit into the big picture. The bigger that puzzle, the bigger the frustration and the more modifications to pieces are needed.
The same thing happens during the global optimization of a map into a single frame, producing and distributing errors throughout that can be difficult to correct. If done poorly, for example, lane boundaries could be shifted so much that our Driver’s path is noticeably “off” from where it should be. Correcting this can be a never-ending battle of ever more expensive optimization and sensor calibration.

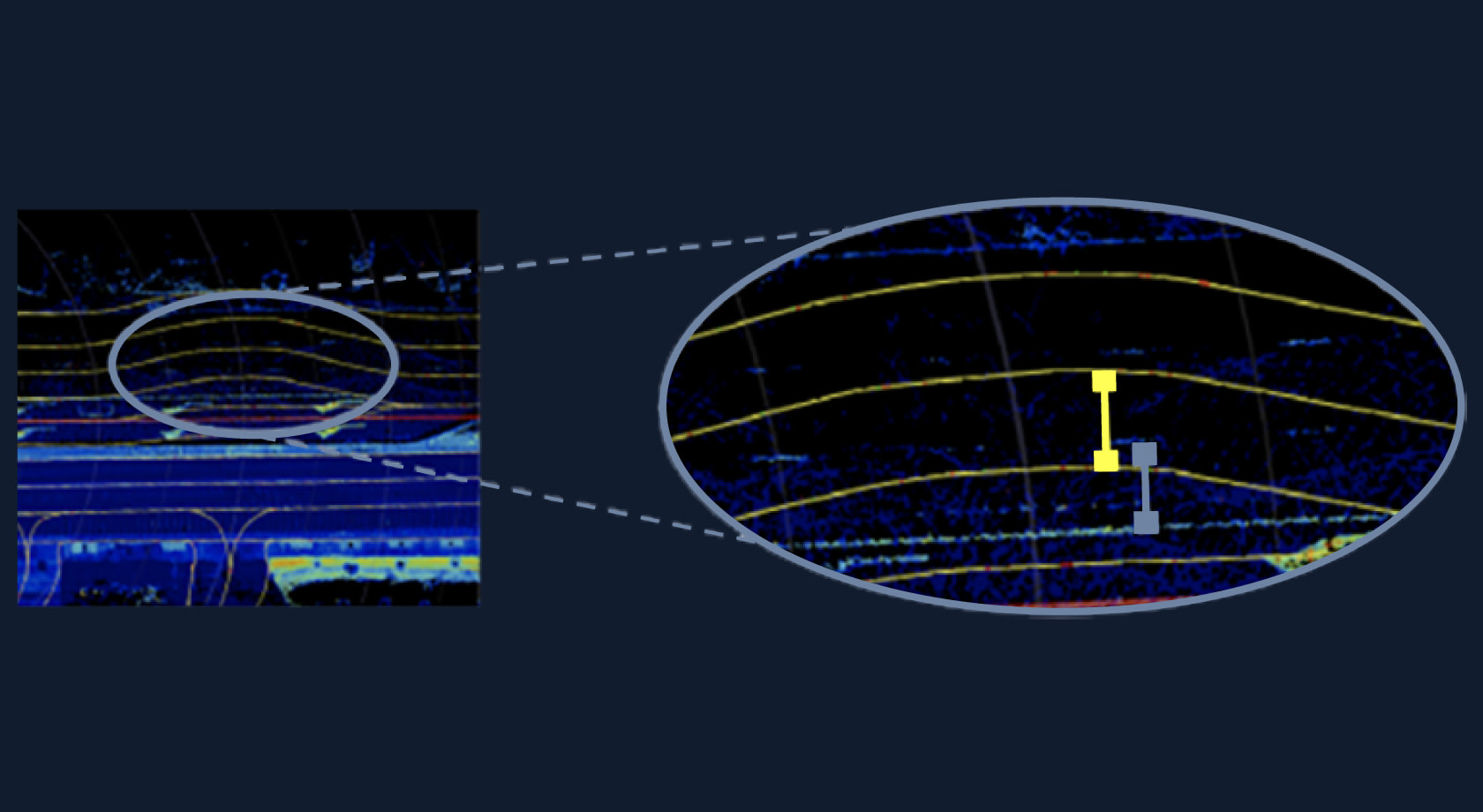
Even after achieving perfect global consistency, we’d have to perform a global optimization on the entire map after every update to maintain it. This adds multiple steps to our pipeline, making the process computationally heavy. While that might be manageable now, it’s not practical at scale.
Fortunately, globally accurate maps simply aren’t necessary for self-driving. Our localization system, which determines the vehicle’s location in the Atlas, doesn’t require global consistency. In fact, we can reliably determine the vehicle’s position and orientation relative to content near the vehicle much more accurately than GPS can.
Further, our Driver hardly ever needs to reason about objects that are far away, so we’re not doing the long-distance comparisons of locations that make globally-consistent data important. Our Driver only ever needs to assemble small pieces of the Atlas at a time. For example, when you’re driving to work, you’re not picturing a map of the entire city as you think about what to do. Instead, you’re scanning the road for pedestrians and worrying about changing lanes for your next turn. Experience has taught us that a precise understanding of where nearby objects (200–300 meters) are in relation to the vehicle is far more important than a globally consistent picture.
Built to Scale
Given our approach using a relative map representation to preserve local accuracy, we don’t build one large map data structure. Instead, our Atlas is sharded into pieces that we stitch together to represent larger areas, like the city of Pittsburgh. These pieces are self-contained and decoupled from one another, giving us the flexibility to update small portions without making changes to the entire map. So when a new stop sign gets added, we can just update that single piece. For reference, each piece of the Atlas is about the size of one city block.
Beyond our sharded, locally accurate design, we’ve invested in developing pipelines and tools that make the Atlas efficient. These will be hugely beneficial as we expand the Aurora Driver to new cities. For example:
Our maps are stored in a versioned database we call the Cloud Atlas that is specially designed to hold Atlas data. Cloud Atlas, which is reminiscent of source control tools like git, keeps a complete record of all Atlas versions and allows multiple map operators to draw and edit annotations concurrently. We’ve also developed accompanying command line tools that allow us to work with Atlas data more efficiently (generating a summary of the differences between versions, retrieving only the data layers we need, etc.).
The annotation and world geometry data layers are updated independently. That means when a city erects a new building, we simply regenerate the geometry layer and lay the existing annotations on top.
We build and maintain custom tools that help our operations team draw accurate annotations faster.
We’ve developed machine learning models that allow us to generate some annotations, like traffic lights, automatically.
Each element of our design interlocks to enable the “broadly” part of our mission. We can rapidly build accurate, lightweight maps in new areas and push updates from the Aurora Cloud to the on-vehicle Atlas in near-real time. We’re investing now in a robust system because we know that our success hinges on producing a high-quality Atlas at scale. This is just one more way that we’re fueling the rockets and building a strong foundation for the Aurora Driver.
We’re hiring Software Engineers and Map Operations Associates to help us continue improving and expanding the Atlas. Visit our Careers page to view open positions and to learn more about what it’s like to work at Aurora.
Related (06)

Introducing Au: Our open source C++ units library

Seeing with Superhuman Clarity: The Physics and Architecture Behind the Aurora Driver’s Perception System

Virtual Testing: The Invisible Accelerator

Aurora’s Verifiable AI Approach to Self-Driving
AI Transparency: The Why and How